HTTP stands for Hypertext Transfer Protocol, and it is the protocol that is used for communication over the web. HTTP is what allows you to view content on a web browser, so for instance when you go to www.google.com, you are greeted with the familiar Google Doodle and search bar.

This dynamic page lives on a server somewhere controlled by Google. It is called a server because it serves something, in this case an html file. HTTP is what allows that file (web page) to be disseminated.
Protocols
There are other protocols besides HTTP, however HTTP is the most common and in some cases has eliminated the need for another protocol. HTTP communicates over the application layer of TCP/IP, which is the Internet’s lower level network protocol.

TCP/IP stands for Transmission Control Protocol/Internet Protocol. TCP/IP is a two layer program, with the higher layer (TCP - Transmission Control Protocol) takes care of breaking down files and messages into packets that are sent over the Internet, and then the TCP layer of the receiver will reassemble the packets back into the original message. The lower layer (IP - Internet Protocol), takes care of addressing the packets so that they arrive to the proper destination.
TCP/IP and HTTP are both communication protocols, however there are big differences in how and where they operate. TCP/IP is the means by which HTTP operates, ensuring that messages get from one place to another over the Internet.
HTTP operates at the application layer, but it is not the only application layer protocol. SMTP (Simple Mail Transfer Protocol), IMAP (Internet Message Access Protocol) and POP3 (Post Office Protocol version 3) are all application protocols that manage sending email messages over the Internet. Each uses a different and specific port on the server for communication.
Another common application layer protocol is DNS (Domain Name System), which is responsible for translating numeric IP addresses to human readable domains. The address to Google’s home page (www.google.com) is a representation of an IP address (like 74.125.0.0). Because Google is such a large service, it has many servers that handle multiple requests to its site, depending on the location of the requester. That means that Google maintains full blocks of IP addresses, which are each translated to www.google.com.
I mentioned that some protocols are no longer used extensively, but they are worth mentioning. FTP (file transfer protocol) was a way to transfer files over a network before the Internet even existed. Some people still use FTP despite the fact that it is insecure and unreliable, likely because it has been around so long (aka ignorance to new and better methods). Another way to transfer files is by BitTorrent, which is a peer to peer distributed protocol. With BitTorrent, one file is provided by several users, each of whom provides little bits of the file when you download, rather than connecting to one particular server for a file.
Characteristics of HTTP
An HTTP request is always initiated by the client. The client will contact another server through a web browser and request a resource. With www.google.com, the resource being requested is the root, since there are no instructions past the initial domain. Here is how a typical url will break down:

The “scheme” in this diagram is also referred to as the protocol. Hey, it’s an HTTP protocol! The host, www.bing.com, is also referred to as the domain. Both the protocol and domain are necessary to get somewhere, but the path and queries are not, and will point to more specific resources beyond the root.
HTTP is stateless. I have spoken about state in previous posts and the idea is similar. Basically stateless in this sense means that each request made via HTTP is independent of previous and future requests. Even if multiple requests are sent on multiple threads to the same socket connection, the requests are still individual because the server is not attaching any special meaning to them. Each request to the server is separate and must contain enough information to satisfy HTTP requirements on its own.
But if HTTP is stateless, what happens when you need to maintain some information, such as keeping items in a shopping cart as you move from page to page? HTTP is stateless because it is not required to track state over multiple requests, but there are still ways to apply state, such as storing information in cookies in the response headers, or through server-side sessions where a user token is stored in a cookie.

Another characteristic of http is that it is a text protocol, meaning that the requests and responses are human-readable. This is good because you can easily monitor the request and response headers, but the extended text does take up more space. There are certainly faster ways of sending data, as in binary, but the tradeoff is requiring some translation step.
Probably one of the best parts of HTTP is that it is extensible to multiple types of responses. While the original use of HTTP was to pass text files, other technologies have come since HTTP was created that still can use the protocol, such as YouTube videos, JavaScript, Google Drive items, and software updates, among other things. All of these items can be served using HTTP where each was created after HTTP. There will surely be even more types not yet imaged for which HTTP will be extended to accommodate.
The reason that this is possible is because the protocol does not care about what the actual message is that is being passed, only that the message has all of the required parts.
HTTP Request
An HTTP request is made up of four parts.
GET /index.html HTTP/1.1
Host: www.google.com
- Request Start Line
- Header Lines (optional)
- Blank Line
- Body (optional)
The request start line will look something like this:
GET http://google.com HTTP/1.1
There are a few pieces in play with the start line. The first part is the method, which in this case is GET. The two most common types of HTTP request methods are GET and POST. The GET method requests data from a resource. A post request, on the other hand, submits data to be processed by a resource. W3 Schools provides a good comparison between these two methods.
Besides GET and POST, other methods are available on some browsers, but some further configuration may be required.

After the method is the URI (Uniform Resource Identifier). A URI can be a URN (name) or URL (location) or a combination of the both. A URL is a type of URI and a URI can be a URL if the network location (ie http://) is included. In the example above, the URI is not a URL because it does not include the network location.
The last piece of the start line is the HTTP version. The common use version currently is 1.1 although HTTP/2 was introduced in 2015 and is available on major browsers.
After the Start line, optional header lines may be included. I will get to these more when I talk about the response line.
What is not optional is the blank line after the start line or header lines. The way that the browser knows that the request is done is with a double newline as a carriage return and line feed. Before the double newline optional body text may also be included.
HTTP Response
The response looks similar to the request, with some slight differences.
HTTP/1.1 200 OK
Date: Mon, 30 May 2015 20:19:40 GMT
Content-Type: text/html; charset=UTF-8
Content-Encoding: UTF-8
Content-Length: 138
Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
Connection: close
<html>
<head>
<title>A Very Simple Page</title>
</head>
<body>
Hello World!
</body>
</html>
- Status Line
- Header Lines (optional)
- Blank Line
- Body (optional)
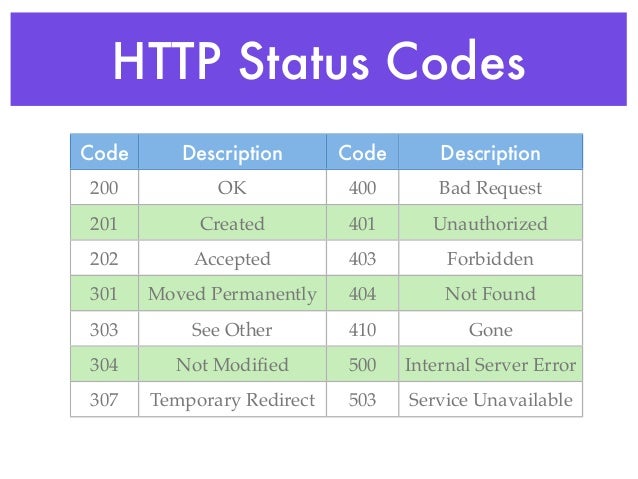
Again, the first line of the response is the start line, but it is broken down differently. The first part is the HTTP version followed by the status code. A status code of 200 is OK, meaning that the resource is available and will be sent back as part of the response body. Another common status code is 404, which shows up when the resource is not available or does not exist.
Following the status code are optional header lines. Wikipedia maintains a list of common and non-common request and response header fields. Header fields for requests or response are just key-value pairs, terminated by a new line (CRLF). The response header allows the server to pass additional information with the response, such as information about the server, as well as information about the file in tow.
Again, following the header lines, you will see a blank line that separates the body. The body will be the contents of the file when dealing with a file server, or whatever the resource is. The body can be a statically set response, or it could come from a parsed file.
Conclusion
HTTP is a protocol that allows information to be passed back and forth between a client and server. HTTP is an application layer protocol in the TCP/IP stack, which is an Internet protocol. There are other types of protocols besides HTTP for file sharing and email. A HTTP request is sent from a client and the server will respond with a resource if it is available.